An AILabs Project
 Click here for simplified version
Click here for simplified version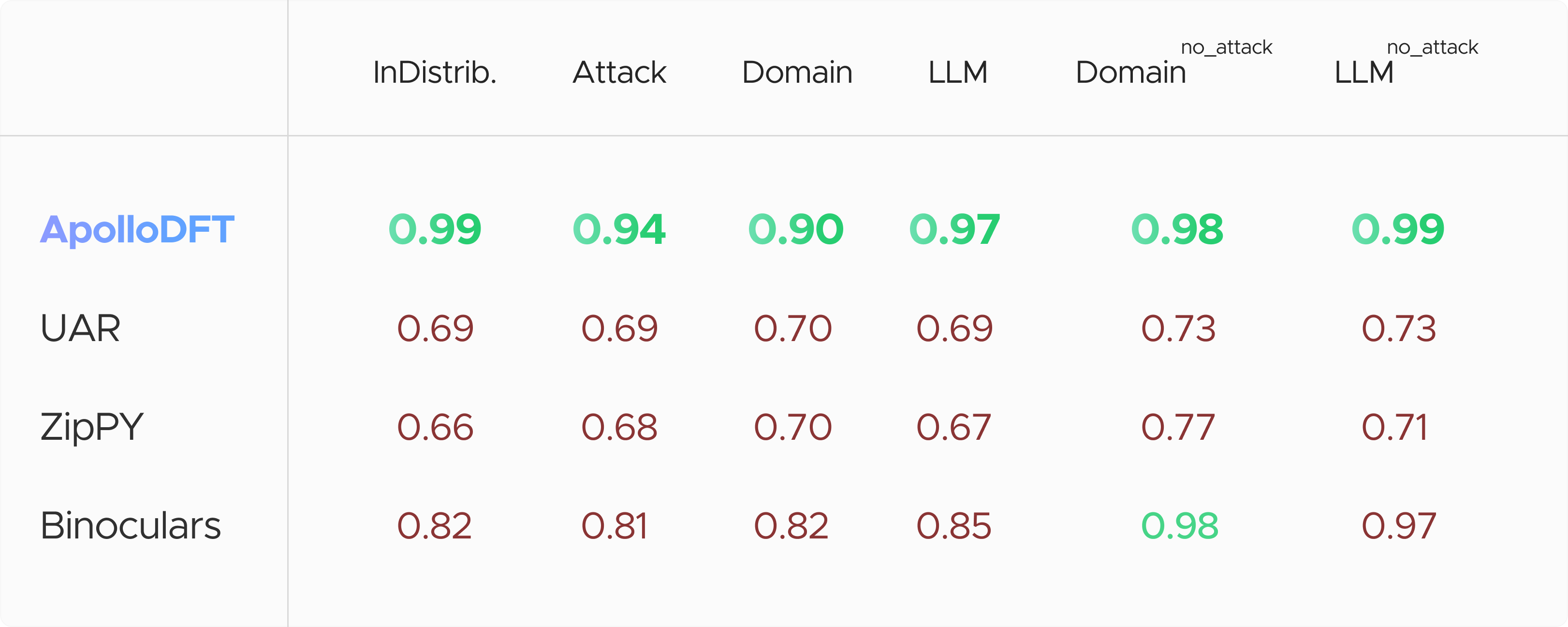
Many LLM detection products report nearly 100% accuracy on their evaluation datasets, but users of these products know the detectors make mistakes. This is likely because these products are evaluated on text that is very similar to their training dataset as seen in the “InDistrib.” column of our results table.
Our training dataset includes as much data as we could collect, but in order to simulate APOLLO’s performance on text encountered by our users,i.e. potentially far from our training set, we evaluated APOLLO in the out-of-domain, out-of-LLM, and out-of-attack settings on the RAID dataset.
For these tests, we hold-out one key slice of data and use what remains for training. The above table reports the average AUROC score across all domains, LLMs, and attacks and should give an idea of how well the APOLLO method generalizes to documents far from our training set. The domain, LLM, and attack scores for APOLLO, while higher than the other methods, give a more realistic but maybe pessimistic view of how the model will generalize to text our users will see in the wilds of the internet.
UAR, zippy, and Binoculars are other open-source methods available in our extension.UAR is a nearest-neighbors based method and leverages a different open-sourced dataset.Zippy is a compression based method and leverages its own dataset as a dictionary.Binoculars is a SOTA zero-shot method that leverages perplexity; notice Binoculars does particularly well on the “no_attack” datasets.Finally, APOLLO is our method; it is an ensemble of both supervised and zero-shot methods to deliver superior detection of AI-generated text across diverse scenarios.We have made the supervised component of the APOLLO method available as open-source. For more details and to view a full report of our benchmark results, please visit our GitHub page.
 Download for Chrome
Download for Chrome






